本文共 1923 字,大约阅读时间需要 6 分钟。
1,分区。
是指按照数据表的某列或某些列分为多个区,区从形式上可以理解为文件夹,比如我们要收集某个大型网站的日志数据,一个网站每天的日志数据存在同一张表上,由于每天会生成大量的日志,导致数据表的内容巨大,在查询时进行全表扫描耗费的资源非常多。那其实这个情况下,我们可以按照日期对数据表进行分区,不同日期的数据存放在不同的分区,在查询时只要指定分区字段的值就可以直接从该分区查找。
下面从用shell命令操作分区表和从hdfs文件系统查看分区表相结合的方式加深对分区表的认识。
第一,创建分区表并将本地文件中的数据加载到分区表中。

要注意的是:首先,创建分区表的时候,要通过关键字 partitioned by (name string)声明该表是分区表,并且是按照字段name进行分区,name值一致的所有记录存放在一个分区中,分区属性name的类型是string类型。当然,可以依据多个列进行分区,即对某个分区的数据按照某些列继续分区。
其次,向分区表导入数据的时候,要通过关键字partition(name=“jack”)显示声明数据要导入到表的哪个分区,这里表示要将数据导入到分区为name=jack的分区。
再次,这里要重点强调,所谓分区,这是将满足某些条件的记录打包,做个记号,在查询时提高效率,相当于按文件夹对文件进行分类,文件夹名可类比分区字段。这个分区字段形式上存在于数据表中,在查询时会显示到客户端上,但并不真正在存储在数据表文件中,是所谓伪列。所以,千万不要以为是对属性表中真正存在的列按照属性值的异同进行分区。比如上面的分区依据的列name并不真正的存在于数据表中,是我们为了方便管理添加的一个伪列,这个列的值也是我们人为规定的,不是从数据表中读取之后根据值的不同将其分区。我们并不能按照某个数据表中真实存在的列,如userid来分区。
第二,查看分区表目录:
通过如下命令查看分区表在文件系统中的存储路径,我们会发现分区所依据的列反应在文件路径上,上面安装name=“jack”分区,实际上是创建了一个文件夹名为name=jack,并将该此导入的数据放置该在文件夹下面。
大家会发现,在下图中当我们使用cat命令查看文件内容时,会发现这个伪列也有显示在客户端,这其实只是显示的一种效果而已,后面我们会同hdfs文件系统查看文件内容,会发现文件中其实没有真正存储这列数据。

第三,查看分区数据:
分区的目的就是提高查询效率,查询分区数据的方式就是指定分区名,指定分区名之后就不再全表扫描,直接从指定分区(如name=jack的分区)中查询,从hdfs的角度看就是从相应的文件系统中(如name=jack文件夹下)去查找特定的数据。如下图所示:

第四,查看分区信息:

第五,向分区中插入数据:

在这个操作中,我们就可以验证分区所依据的列其实是一个伪列,如果你要从具有相同结构的分区表中导入数据,会失败。比如两个分区表,都有两个真实的列和一个分区列(伪列),我们要将一个分区表中的数据导入到另一个分区表,会报错。错误信息显示要导入的表只有两列(伪列不记在内,这说明其实数据表文件中只有两列),而源表却有三列(将伪列计算在类),我觉得这是一个bug。
2,分桶。
分桶是相对分区进行更细粒度的划分。分桶将整个数据内容安装某列属性值得hash值进行区分,如要安装name属性分为3个桶,就是对name属性值的hash值对3取摸,按照取模结果对数据分桶。如取模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件。
第一,如何分桶:

注意:第一,分桶之前要执行命令.enforce.bucketiong=true;
第二,要使用关键字clustered by 指定分区依据的列名,还要指定分为多少桶,这里指定分为3桶。
第三,与分区不同的是,分区依据的不是真实数据表文件中的列,而是我们指定的伪列,但是分桶是依据数据表中真实的列而不是伪列。所以在指定分区依据的列的时候要指定列的类型,因为在数据表文件中不存在这个列,相当于新建一个列。而分桶依据的是表中已经存在的列,这个列的数据类型显然是已知的,所以不需要指定列的类型。
第二,向桶中插入数据:

第三,查看桶信息:

由上图可知分3个桶就是将数据表由一个文件存储分为3个文件存储。
第四,查看分桶数据:

要指定关键字tablesample。
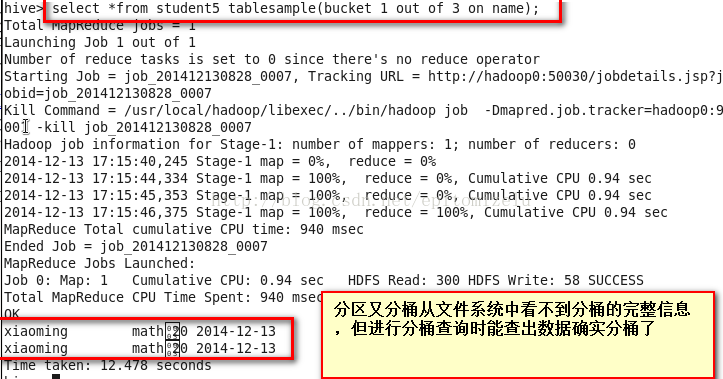
3,分区又分桶。
可以对数据表分区之后继续分桶。
但是分区之后继续分桶,我们在hdfs文件系统上看不出分桶的多个数据表文件,只能看见一个文件,但是能从文件路径上看出分区的信息。

看看分区又分桶的查询结果: